
1- What is ETL?
ETL, or extract, transform, and load, is a method of integrating data that gathers information from several sources into a single, consistent data store that is then put into a data warehouse or other targeted system.
ETL was introduced as a way for integrating and loading data for computation and analysis as databases gained in popularity in the 1970s, eventually taking over as the main technique for processing data for data warehousing projects.
ETL lays the groundwork for workstreams in data analytics and machine learning. By a set of business standards, ETL cleans and arranges data in a way that satisfies business intelligence requirements, such as monthly reporting, but it can also handle more complex analyses that can enhance back-end operations or end-user experiences.
It’s easy to believe that building a data warehouse only requires importing data from various sources into the database of the data warehouse. This is untrue and calls for a challenging ETL procedure. The ETL process is technically difficult and demands active participation from a variety of stakeholders, including developers, analysts, testers, and senior managers.
Data warehouse systems must adapt to business changes if they are to continue serving as valuable decision-making tools. ETL must be quick, automated, and thoroughly documented because it occurs often (daily, weekly, or monthly) in a data warehouse system.
ETL is frequently used by a business to:
• Extract information from old systems
• Improve the data’s quality and consistency by cleaning it up.
• Load information into the desired database.
2- Why We Need ETL?
Adopting ETL inside the organization is for a variety of reasons, including:
• It aids businesses in the analysis of their company data for important business decisions.
• Complex business problems that an ETL example can resolve cannot be resolved by transactional databases.
• A data warehouse offers a central data repository.
• ETL offers a way for transferring data into a data warehouse from several sources.
• The Data Warehouse will continuously update itself as data sources change.
• A successful ETL system that is well-designed and documented is practically required for a Data Warehouse project to be successful.
• Make data transformation, aggregation, and computation rules verifiable.
• Comparing sample data between the source and target systems is possible with ETL.
• ETL processes can carry out intricate transformations and need more space for data storage.
• ETL assists in the migration of data into a data warehouse. To maintain a single, unified system, convert to the different formats and types.
• ETL is a predetermined procedure for gaining access to and altering source data in the targeted database.
• ETL provides the company with rich historical context through the data warehouse.
• It boosts productivity by codifying and reusing information without requiring technological knowledge.
3- Detailed ETL Process
Extract, Transform, and Load, or ETL, is a Data Warehousing process. An ETL tool extracts the data from several data source systems, transforms it in the staging area, and then puts it into the Data Warehouse system.
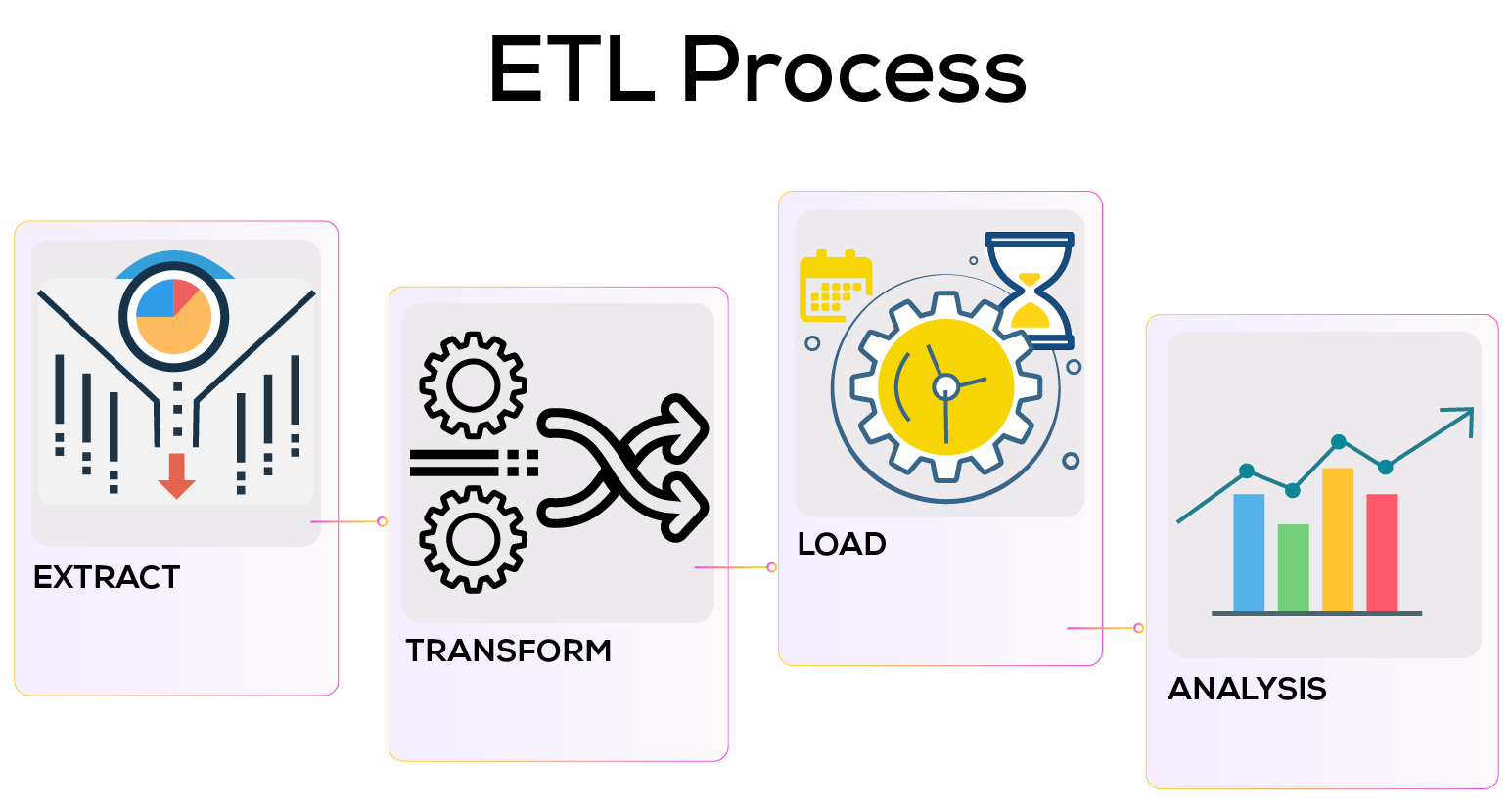
Let’s examine each phase of the ETL process in detail:
Extraction: The ETL process starts with this phase. In this stage, data from multiple source systems is retrieved and placed in the staging area in a variety of forms, including relational databases, No SQL, XML, and flat files. Because the extracted data is in different formats and might be damaged as well, it is vital to extract the data from several source systems and store it in the staging area before putting it straight into the data warehouse. Thus, adding it straight into the data warehouse might harm it, making reversal considerably more challenging. Consequently, this is one of the most crucial phases in the ETL process.
There are three data extraction methods.
• Full Extraction
• Partial Extraction- Without updated notification
• Partial Extraction- With updated notification
Transformation: Data extracted from the source server is unprocessed and unusable in its current state. This calls for its cleaning, mapping, and transformation. This is the crucial stage when the ETL process provides value and transforms the data so that intelligent BI reports may be produced.
One of the key ETL principles is the implementation of a set of functions on extracted data. Data that doesn’t need to be transformed is referred to as straight move or pass-through data. You can apply customized operations to data during the transformation process. For instance, suppose the user requests a sales revenue total that is not stored in the database. Or if a table’s first and last names are in distinct columns. Before loading, you may concatenate them.
Loading: The last phase of ETL involves loading data into the target data warehouse database. A large volume of data must often be put into a data warehouse in a short amount of time. Therefore, performance optimization of the load process is necessary.
Recovery mechanisms should be set up such that they can resume operations without losing data integrity in the occurrence of a load failure. Data warehouse administrators must keep an eye on, resume, or cancel loads based on the current server performance.
There are three loading methods:
Initial Load: which involves loading up all the Data Warehouse tables
Incremental load: Applying continuous modifications as necessary in a recurrent manner.
Full Refresh: erasing the information in one or more tables and loading new information.
4- Technical aspects of the ETL Process
The following must be carefully considered while creating your ETL processes:
Correct Data logging: It’s crucial to ensure that your data system performs “accurate logging” of new data. You must audit the data after loading to look for faulty or missing files to ensure proper recording. When problems with data integrity develop, you may troubleshoot your ETL process by using correct auditing processes.
Structured and unstructured data compatibility: Your data warehouse may need to combine data from several disparate, incompatible sources, including PostgreSQL, Salesforce, Cassandra, and internal finance applications. There’s a chance that some of this data lacks the analytically necessary data structures. To address these issues, you must build your ETL process compatibility with structured or unstructured schema.
Reliable and Stable System: ETL pipelines can get overloaded, crash, and have other issues. To ensure that your data can travel without being lost or damaged even in the face of unforeseen challenges, your objective should be to develop a fault-tolerant system that can resume after a shutdown.’
Alert Enabled System: An alert system that warns you of possible issues with the ETL process is necessary to guarantee the accuracy of your business insights. For instance, you’ll want to get alerts and reports on things like expired API credentials, third-party API problems, connector errors, general database errors, and more.
Fast Data Acceleration Techniques: Data warehouses and BI systems can provide better, more accurate insights at a moment’s notice when they have access to current data. Because of this, it’s critical to concentrate on reducing data latency, or the time it takes for a data packet to transit from one part of the system to the next.
Growth adaptability: Your ETL solution should have the ability to scale up and down in response to the shifting data requirements of your firm. As a result, processing and storage costs on cloud servers will be reduced, and scaling up as needed will be possible.
Incremental Loading Support: By enabling incremental loading, change data capture (CDC) speeds up the ETL process. This enables you to update a small portion of your data warehouse while maintaining data synchronization.
5- ETL Vs. ELT
The order of operations between ETL and ELT differs significantly, which is the most noticeable distinction. ELT exports or copies the data from the sources, but instead of putting it into a staging area for transformation, it loads the raw data straight into the destination data store to be modified as required.
Although both methods make use of different data sources, including databases, data warehouses, and data lakes, each approach has pros and cons. ELT is especially helpful for large, unstructured datasets since it allows for direct source loading. Since ELT requires less advanced preparation for data extraction and storage, it may be more suitable for big data management. On the other side, the ETL process needs greater clarity from the start. To extract certain data points from various source systems, as well as any potential “keys” to integrate them, certain data points must be discovered. The creation of the business rules for data transformations is still required even after that task is finished. The amount of summarization that the data requires will rely on the data requirements for a particular form of data analysis, which might often depend on this effort. ELT has its drawbacks
because it is a relatively recent technique, meaning that best practices are still being developed, although growing in popularity along with the adoption of cloud databases.
6- ETL Tools
There are numerous ETL tools are available in the market. Here are some of the most notable ones:
Mark Logic:
Mark Logic is a data warehousing system that uses a variety of corporate capabilities to simplify and accelerate data integration. It can query several sorts of data, including relationships, documents, and metadata. It can query a variety of data types, including relationships, documents, and metadata.
Oracle:
The most widely used database is Oracle. Both on-premises and in the cloud, it provides a wide range of options for Data Warehouse solutions. Improving operational effectiveness, aids in optimizing the client experience. Improving operational effectiveness contributes to the improvement of consumer experiences.
Amazon RedShift:
Redshift is a data warehousing product from Amazon. Using common SQL and current BI tools, it is an easy and reasonably priced solution for analyzing various forms of data. Additionally, it enables the execution of advanced searches against petabytes of structured data.



